
Privacy and security is funmental of intenet, no such company should vaiolating users rights and running experiments on users, especially when that is not listed on privacy policy of their services.
Few days back you have heard the new open Ai’s Chagpt problem on Mac reported here https://www.theverge.com/2024/7/3/24191636/openai-chatgpt-mac-app-conversations-plain-text
We started invesataging on Chatpgt and we have notieced that one of Open AI’s Emplyee running experiments on user with using his personal website.
There are significant issues in these experiments. Firstly, according to OpenAI’s privacy policy listed here https://openai.com/policies/privacy-policy/, users should remain unidentified and anonymous if they do not log in.

However, this experiment indicates that users are being identified by a unique ID stored in their web browser for future use.
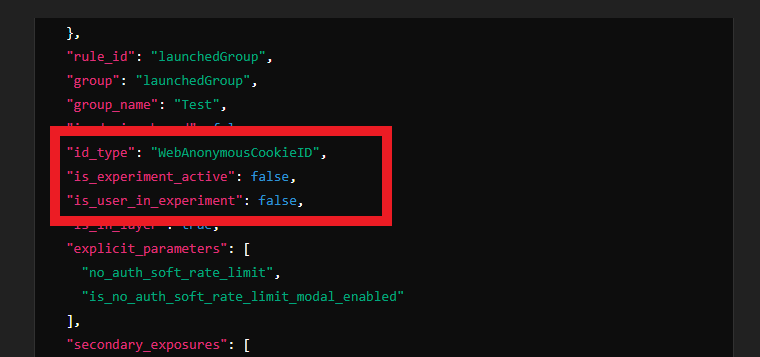
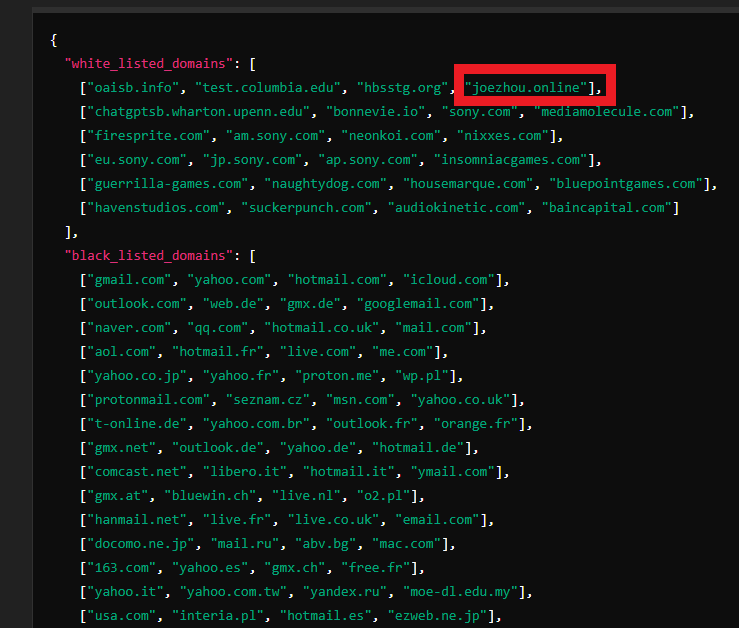
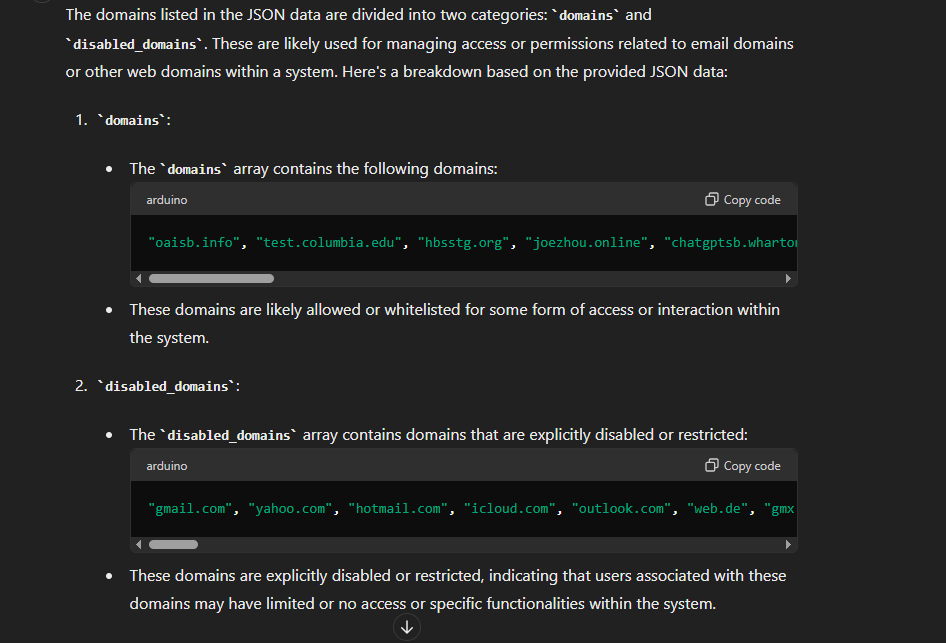
Secondly, we have observed that these experiments are conducted using two lists: a whitelist of websites and a blacklist of websites.
This is how we were able to discover who is behind these experiments: the new employee of OpenAI, Joe Zhou, recently joined OpenAI and registered a website under his name to conduct these experiments on users.
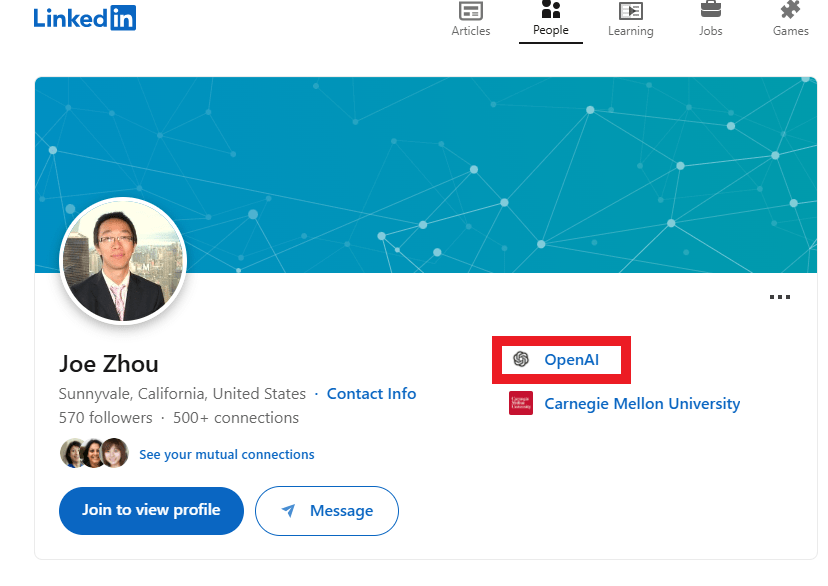


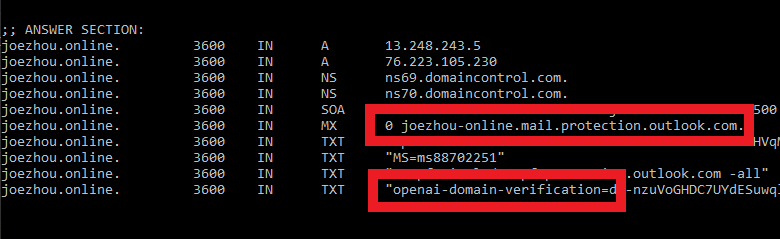
You might say the employee is running this for QA testing on his personal website, but what about domains like Sony.com or columbia.edu?, after nearly 20 years in cybersecurity, we’ve never seen such a QA test conducted on end users. That’s just unacceptable.
Saving private messages on your PC is different from running an experiment using an employee’s personal website; that crosses several red lines.
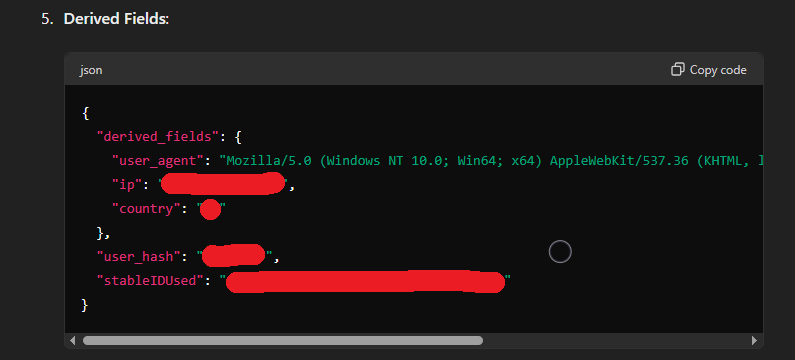
Normally, you can’t see what is going on with OpenAI’s website and your web browser. Here, we injected into the web browser process and extracted all this data, as you can see in the following:
These experiments use two whitelisted and blacklisted domains and only work on certain users; it’s not active for all users.

If you have any questions, we would be happy to answer them. Please comment below.
Conclusion
As language models continue to evolve and integrate into various aspects of our daily lives, ensuring their security against jailbreaking is paramount. Protecting these models not only preserves data integrity and privacy but also upholds their trustworthiness and reliability in delivering accurate and unbiased information.
At Venak Security, we offer excellent online security services to protect your AI company from being targeted by jailbreakers or your employees. Please check out our services for more information and let us know how we can assist you!


Leave a Reply